평균
Posts
9 posts
극단적인 사람만 사는 세상
1. 평균이 실질적으로 우리를 대표합니다. 싫든 좋든 평균이 우리가 살아가는 세상입니다. 정작 대부분 사람들은 자신이 평균이라는 걸 잊고 살아갑니다. 평균은 재미가 없어 그런지도 모르겠습니다. 2. SNS를 보면 항상 극단이 넘쳐납니다. 인기를 끄는 건 대부분 극단값입니다. 엄청나게 부자이거나 당장 망할 것 같은 사람. 이런 사람들만이 주목을 받습니다. 3. 과연 저들이 하는 말이 진짜인지 의심될 때가 너무 많습니다. 자신이 하는 말을 스스로도 달성하지 못하는 상황. 흔히 이야기하는 입으로만 떠드는 거죠. 이런 경우는 너무 많이 보게 됩니다. 4. 블로그로 월 천을 벌 수 있다고 합니다. 그걸 외치는 블로그보다 유튜브가 더 많더.......
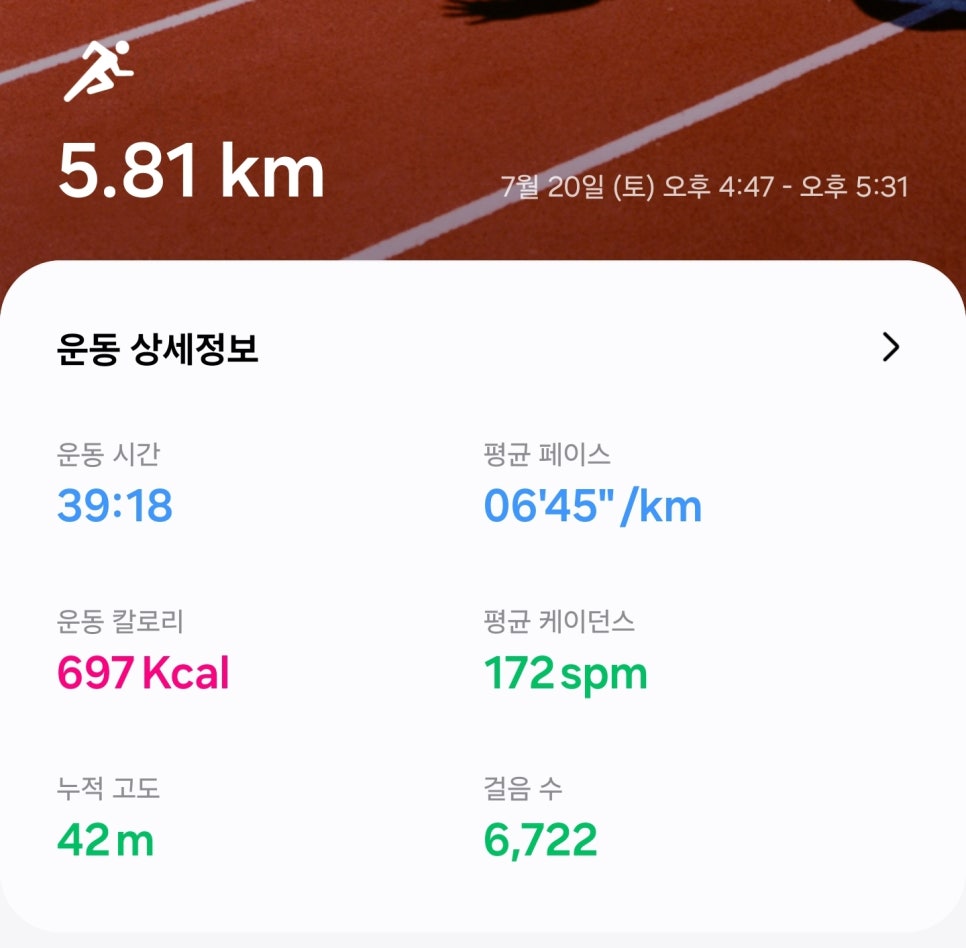
평균의 중요성
1. 가끔 평균으로 이야기할 때가 있습니다. 평균으로 보면 오류에 빠질 때가 있습니다. 평균이 무척이나 우습게 보일 때도 있고요. 달리기를 하면 평균이 나옵니다. 2. 평균만 본다면 큰 차이가 나지 않는 것처럼 느껴집니다. 평균 6분이나 6분 5초나. 겨우 5초 차이밖에 안 나는 것처럼 느껴지죠. 이게 5km를 뛴다면 이야기가 또 달라집니다. 3. 25초가 차이납니다. 25초가 또 큰 차이가 아닌 것처럼 느껴지기도 합니다. 이걸 거리로 하면 또 달라집니다. 아마도 25초면 제 앞에서 뛰는 게 보이지도 않을 겁니다. 4. 보통 100미터 육상 경기를 보면 알 수 있죠. 진짜 찰나의 순간처럼 보이는데요. 거리가 1M 이상 차이날 때가 있습니다. 그만큼.......
datamash - 리눅스에서 합, 평균, 표준편차 계산
리눅스에서 텍스트 파일에 저장된 수자들로부터 합, 평균, 표준편차 등을 계산하고 싶을 때 datamash를 활용할 수 있다. 설치는 터미널창에서 아래와 같이 진행한다. 데비안/우분투 기준이다. # S/W 저장소 정보 갱신 sudo apt-get update # datamash 설치 sudo apt-get install datamash 예를 들어 과일의 개수를 저장한 fruits.txt 파일의 내용이 아래와 같다고 가정하자. apple 10 banana 24 grapes 17 첫번째 항목은 명칭이고 두번째 항목은 개수이다. 전체 과일의 개수는 아래와 같이 계산할 수 있다. # 두번째 항목의 합 cat fruits.txt | datamash sum 2 "sum 2"
[bash:awk] awk를 이용한 평균값 계산
awk를 이용해서 파일에 저장된 값들의 평균을 계산하는 방법이다. 우선 data.txt 파일에 아래와 같은 값이 저장되어 있다고 가정하자. # data.txt 내용 확인 cat data.txt john 12.35 jane -34.5 thomas 3.9 위와 같은 내용으로 저장되어 있을 때, 평균을 계산하려면 아래와 같이 가능하다. awk '{ sum += $2; cnt++ } END { print sum/cnt }' data.txt -6.08333 data.txt의 두번째 항목($2)을 더해서 변수 sum에 저장하고, 자료값의 수를 세기 위해 변수 cnt도 1씩 증가. 합산 작업이 끝나면(END) 합(sum)을 자료값의 수(cnd)로 나누면 평균이 된다. 만약 파일



