FORTRAN90
Posts
4 postsanaconda, 파이썬 설치와 딥러닝 준비 [keras --> tf.keras]
아나콘다? 아나콘다는 패키지 관리와 디플로이를 단순케 할 목적으로 과학 계산을 위해 파이썬과 R 프로그래밍 언어의 자유-오픈 소스 배포판이다. 패키지 버전들은 패키지 관리 시스템 conda를 통해 관리된다. 아나콘다 배포판은 1300만 명 이상의 사용자들이 사용하며 윈도우, 리눅스, macOS에 적합한 1,400개 이상의 유명 데이터 과학 패키지가 포함되어 있다. anaconda, 파이썬 설치와 딥러닝 준비 [keras --> tf.keras] 아나콘다에 텐서플로를 설치하면 곧바로 딥러닝을 시작할 수 있다. Tensorflow 2.0으로 새롭게 시작하는 tensorflow keras --> tf.keras 파이썬 실행환경 구축, 딥러닝 환경구축:anaconda 설치 [32bi
가장 쉬운 변수 공유 (클래스를 활용한 변수 공유) [Python]
가장 쉬운 변수 공유 (클래스를 활용한 변수 공유) [Python] 포트란 77의 common 문 사용과 같이 특정 변수들을 한 곳에 모아 두고 다른 서브루틴들이 특정 무리 변수들을 활용할 수 있게 할 수 있다. 변수들의 종류별로 사용자가 이름을 붙인 common 문을 선언하면 보다 더 구체적인 변수 무리들을 별도로 관리할 수 있다. 또한, 이들 common 문을 별도의 파일 속에 넣고 파일로 저장할 수 있다.특정 변수들이 필요한 경우 그 파일을 include 하는 방식으로 프로그램을 편집할 수 있다. 이렇게 전체 프로그램을 관리할 수 있다. 이렇게 할 경우, 흩어져 있을 수 있는 common 문 변수들이 완전히 동일하게 편집된다.강제적으로 동일한 하나의 내용물이 되게할 수 있다. 즉, 꼭 필요한 서브루틴
fortran unformatted file --> read in python
fortran unformatted file --> read in python기계학습에서 다루는 데이터의 크기는 매우 큰 것들이다. 특히, 딮러닝의 경우는 더욱더 그렇다.따라서, 데이터 처리는 정말로 특별한 장치가 필요하다. 바이너리 파일 취급이 필수적이다.기본적으로 아스키 파일을 사용하면 곤란해질 수 있다.많은 예제 데이터를 만들어 낼 경우, 컴퓨터 프로그래밍 언어 파이썬은 정답이 아닐 수 있다.이 경우 포트란 또는 C를 활용해야 한다. 당연하게도 데이터는 바이너리 파일로 저장해야만 한다. 이렇게 저장된 바이너리 파일은 파이썬에서 바이너리 형식으로 읽어져야만 한다.그래야 전체 파이썬 계산의 효율성을 극대화 할 수 있다.다른 방식으로 파일 처러를 하면 안 된다.예를 들어, 예제들의 갯수가 200000인
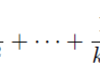
Basel problem
Basel problem . 파이썬, 포트란 90 컴퓨터 프로그램을 활용하여 수치적으로 위의 공식의 타당성을 체크해보고자 한다.특히, 파이썬 언어로 작성된 컴퓨터 프로그램의 계산 속도 향상을 위하여 pypy를 사용해 본다.http://pypy.org/ cat basel.py #!/usr/bin/env python #Basel problem import timedef recip_square(i): return 1./i**2def approx_pi(n): val = 0. for k in range(1,n+1): val += recip_square(k) return (6 * val)**.5start=t




